SQL Server İle Veri Tabanı İşlemleri #2
Bu yazıda sizlere SQL’de ilişkili tablolardan, SUM(), AVG(), MIN(), MAX() gibi Aggregate fonksiyonlarından, sütunların takma ad ile çağrılmasından, Between ve Distinct gibi komutlardan bahsedeceğim.
İlişkili Tablolar
İlişkili tabloları daha iyi anlayabilmek için bir personel tablomuzun olduğunu varsayalım. Bu tabloda personellerimizin adı, soyadı, yaşı, maaşı, departmanı, mesleği ve cinsiyeti gibi bilgiler olsun.
USE PersonelBilgileri
CREATE TABLE PersonelTablosu(
ID INT IDENTITY(1,1) PRIMARY KEY,
Ad Varchar(30),
Soyad Varchar(30),
Cinsiyet Char(1),
Yas TINYINT,
Maas DECIMAL(7,2),
Departman INT,
Meslek INT
)
Eğer bu şirketin çalışan sayısı çok fazla ise (örneğin 1000 ya da daha fazla) bu personellerin departmanları ve meslek bilgileri bellekte fazla yer tutmaya başlar. Bu sebeple her personelin departman ve meslek bilgisini yazmak yerine departman bilgilerini ve meslek bilgilerini tutan iki tablo oluşturabiliriz.
USE PersonelBilgileri
CREATE TABLE Departman(
ID INT IDENTITY(1,1) PRIMARY KEY,
DepartmanAdi Varchar(30)
)
CREATE TABLE Meslek(
ID INT IDENTITY(1,1) PRIMARY KEY,
MeslekDepartmanı INT,
MeslekAdi Varchar(30)
)

Böylece personelin departmanının adını ve meslek adını yazmak yerine o departman ve meslek bilgisinin ilgili tablolardaki ID’lerini yazabiliriz. Örneğin personelin mesleği Bilgisayar Mühendisliği ise bu bilgiyi yazmak yerine meslekler tablosundan Bilgisayar mühendisliğinin ID numarasını yazabiliriz. Bu şekilde yaklaşık olarak 19 karakter fazladan bellekte bellekte yer tutmamış olacağız. Yaptığımız bu işlemle meslekler ve departmanlar tablosu ile personel tablosu ilişkili hale gelmiş olur. 3 tip ilişki türü vardır. Bunlar bire-bir ilişki, bire-çok ilişki ve çoka-çok ilişkidir. Bunları bu yazıda detaylı olarak anlatmayacağım. Bizim kullanacağımız genelde bire-çok ilişki türü olacaktır.
Bu tabloların ilişki içerisinde olduğunu SQL’in anlaması için bu ilişkiyi SQL üzerinde tanımlamamız gerekir. Bunun için Object Explorer penceresindeki Database Diagrams klasörüne sağ tıklayıp New Database Diagram’ı seçmemiz gerekir. Karşımıza gelen pencereden hangi tablolar ilişki içerisinde ise seçilmesi gerekir. Burada önemli bir husus daha vardır. Tablolarımızdaki ID sutununu Birincil Anahtar (Primary Key) olarak tanımlamış olmamız gerekir. Primary Key satırların birbirleri ile karışmaması ve ayırt edilebilmesi için kullanılan benzersiz alanlardır. Genellikle ID alanları için kullanılır. Bir sütunu birincil anahtar olarak tanımlamayı tablo yaratırken komut ile belirleyebileceğimiz gibi sonradan da belirleyebiliriz. Örnek olarak:
CREATE TABLE DenemeTablosu(
ID INT IDENTITY(1,1) PRİMARY KEY,
……
)
verilebilir. Bu örnekte ID alanının birincil anahtar olduğunu ve 1’den başlayıp her bir satır için 1’er 1’er artması gerektiğini söyledik.
Eğer tablo üzerinden düzenleme yapabilme iznimiz var ise tablomuzdaki ID sütununa sağ tıklayıp “set primary key” dersek birincil anahtar olarak belirlemiş oluruz.
Bunun dışında Birincil anahtara çok benzeyen benzersiz anahtar (Unique Key) vardır. Birincil anahtardan farklı boş değer(null) alabiliyor olmasıdır.
Birincil anahtar olmayan ve başka bir tablo ile ilişkilendirilebilen alanlara ise Yabancıl Anahtar denir. Örneğin Personel tablosundaki departman ve meslek sütunları yabancıl anahtardır.
İlişkilendirmek istediğimiz tabloları seçtikten sonra hangi tabloların birincil anahtarları hangi tabloların yabancıl sütunu ile ilişkilendirilecekse, birincil anahtar sürüklenip yabancıl anahtarın üzerine bırakılmalıdır.

Böylece artık yabancıl anahtardaki değer birincil anahtarın olduğu tablodaki bir veriyi temsil eder. Örneğin personel tablosundaki Adil Kaşıkçı adlı personelin mesleğine 6 yazıldığından, meslekler tablosunda ID numarası 6 olan meslek bu personelin mesleği olur. Meslekler tablosunda ID numarası 6 olan meslek şef olduğundan Adil Kaşıkçı adlı personelin mesleği şef olmuş olur. SQL bunu anlar.
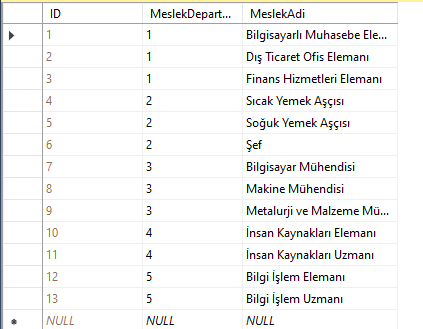
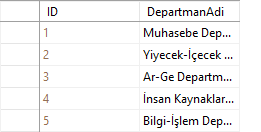
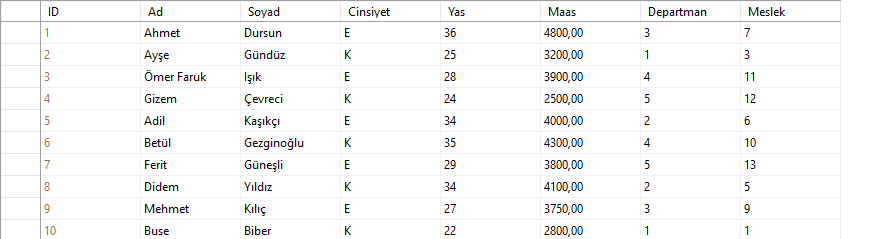
Ancak biz listeleme yaparken personel tablosunu listelediğimizde bu personellerin departman ve meslek sütunları hala sayı olarak görünür. Eğer bu sütunların meslek ve departman adları ile görünmesini istersek birleştirmeleri kullanmamız gerekir. Bu konudan sonraki yazılarda bahsedeceğim. Şu ana kadar en az iki tablonun nasıl ilişkilendirileceğini gördük. Eğer ilişkide düzenleme ya da değişiklik yapacaksak Database Diagrams klasörünün altındaki ilişki diagramımıza sağ tıklayıp “modify” dememiz yeterli olacaktır. Açılan diagramda istediğiniz düzenlemeyi yapabilirsiniz.
Aggregate Fonksiyonları
Aggregate fonksiyonları bir tabloda kullanılabilecek SUM(), AVG(), COUNT(), MIN() ve MAX() gibi fonksiyonlardır. Bu fonksiyonları kullanarak örneğinm personel tablosunda personel sayısı, ortalama maaş, ortalama yaş ve en genç personel gibi değerler bulunabilir. Aggregate fonksiyonları Select komutu ile birlikte kullanılır. Bu komutlar aşağıdaki gibi özetlenebilir:
SUM()
İstenen sütunlardaki tüm veriyi toplamak için kullanılır. Toplaması yapılan sütunun sayısal değerlerden oluşması gerekir. Örnek kullanımı aşağıdaki gibidir:
SELECT SUM(sütun adı) FROM (tablo adi)
Eğer ihtiyaç duyulursa bu komuta şartta bağlanabilir. Örneğin yaşı 25’ten küçük olanların maaşı nedir? Dersek,
INPUT:
SELECT SUM(Maas) FROM PersonelTablosu WHERE Yas<25
OUTPUT:
5300.00 sorgusunu kullanılabiliriz.
AVG()
İstenilen sütunlardaki ortalamayı hesaplamak için kullanılan komuttur. Örneğin personel tablosunda ortalama yaşı bulmak istersek,
INPUT:
SELECT AVG(Yas) FROM PersonelTablosu
OUTPUT:
29sorgusunu kullanılabiliriz.
COUNT()
İstenen sütunlardaki verileri saymak için kullanılan komuttur. Örneğin personel tablosunda kaç tane veri olduğunu öğrenmek istiyorsak,
INPUT:
SELECT COUNT(*) FROM PersonelTablosu
OUTPUT:
10sorgusunu kullanabiliriz. Bir başka örnek olarak personel tablosunda maaşı 3000 TL’den büyük olan personellerin sayısını öğrenmek istersek,
INPUT:
SELECT COUNT(*) FROM PersonelTablosu WHERE Maas>3000
OUTPUT:
8sorgusunu kullanabiliriz.
MIN()-MAX()
İlgili sütuna ait en küçük ve en büyük değerleri listelemek için kullanılan komutlardır. Örneğin personel tablosundaki en genç ve en yaşlı personellerin yaşlarını listelemek istersek,
INPUT:
SELECT MIN(Yas) FROM PersonelTablosu
OUTPUT:
22INPUT:
SELECT MAX(Yas) FROM PersonelTablosu
OUTPUT:
36sorgularını kullanabiliriz.
Bir başka örnek olarak şirketimizde en az maaş alan kişinin ne kadar maaş aldığını listelemek istersek,
INPUT:
SELECT MIN(Maas) FROM PersonelTablosu
OUTPUT:
2500.00sorgusunu kullanabiliriz.
Böylece Aggregate fonksiyonlarından bahsetmiş olduk. Şimdi ise listeleme yaparken listelediğimiz herhangi bir sütunu takma ad ile nasıl listeleyebileceğimizden bahsedelim.
ALIAS İFADESİ
Yukarıdaki örneklerde ortalama yaşı listelemek için bir sorgu komutu kullandık. Bu sorgu çalıştıktan sonra sonuç bize görünür ancak sütun adı “No Column Name” olarak görünür.
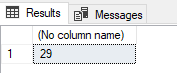
Eğer burada listelemek istediğimiz sonuç bir sütun adı ile görünsün istersek Alias ifadesini kullanmamız gerekir. Bu ifade sorguda AS olarak yazılır. Bahsettiğim örneği tekrar yazmak istersek,
INPUT:
SELECT AVG(Yas) AS “Ortalama Yaş” FROM PersonelTablosu
sorgusunu yazabiliriz.
NULL DEĞERLER
SQL’de eğer bir satırın herhangi bir sütununa değer girilmemiş ise o sütun NULL olarak görünür. Listemele yaparken NULL değeri bulunan verileri listelemek mümkündür.
DISTINCT KOMUTU
Bir tablodaki herhangi bir sütunda bulunan benzersiz verileri listelemek için kullanılan komuttur. Örneğin personel tablosunda isimleri benzersiz olanları listeleyelim.
INPUT:
SELECT DISTINCT(Ad) FROM PersonelTablosu
OUTPUT:
Adil
Ahmet
Ayşe
Betül
Buse
Didem
Ferit
Gizem
Mehmet
Ömer FarukBETWEEN OPERATÖRÜ
Bir tablodaki herhangi bir sütun için istediğimiz alt ve üst limitler arasındaki değere sahip verileri listelemek için kullanılan komuttur. Örneğin Personel tablosundaki yaş aralığı 30-35 ve maaş aralığı 2800-4000 TL olan verileri listeleyelim.
INPUT:
SELECT * FROM PersonelTablosu WHERE Yas BETWEEN 30 AND 35 AND Maas BETWEEN 2800 AND 4000
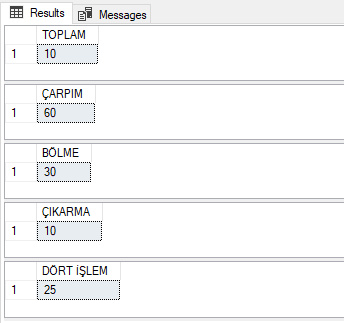
Bunların dışında kısaca aritmetik işlemlerden bahsetmek istiyorum. SQL’de aritmetik işlem yapmak herhangi bir programlama dilinde işlem yapmaya benzerdir. Aritmetik işlemler Select komutu ile kullanılabilir. Yapılmak istenen işleme göre matematiksel operatör kullanılarak aritmetik dört işlem gerçekleştirilir. Birkaç örnek gösterip yazımızı sonlandıralım.
INPUT:
SELECT 4+6 AS "TOPLAM"
SELECT 10*6 AS "ÇARPIM"
SELECT 60/2 AS "BÖLME"
SELECT 30-20 AS "ÇIKARMA"
SELECT (((30-5)+10)/7)*5 AS "DÖRT İŞLEM"