RAG mimarisi, LLM tabanlı sistemlerin dış bilgi kaynaklarıyla desteklenerek daha doğru ve bağlama dayalı cevaplar üretmesini mümkün kılar. Ancak bu tür sistemlerde asıl kritik konu, yalnızca cevabın üretilmesi değil; üretilen cevabın ne kadar güvenilir, tutarlı ve tekrar edilebilir olduğunun doğrulanmasıdır. Bu noktada klasik yazılım test yaklaşımları yetersiz kalır ve LLM’lere özgü yeni değerlendirme kriterlerine ihtiyaç duyulur.
Bu yazıda, RAG mimarili bir LLM’in çıktı kalitesini ve bağlam kullanımını değerlendirmek için kullanılan standart QA metriklerine odaklanacağız. Retrieval adımının doğruluğundan üretilen cevabın bağlama sadakatine, olgusal doğruluktan cevap uygunluğuna kadar uzanan bu metriklerin hangi riskleri ölçtüğünü, nasıl yorumlanması gerektiğini ve QA süreçlerinde nasıl konumlandırılabileceğini ele alacağız.
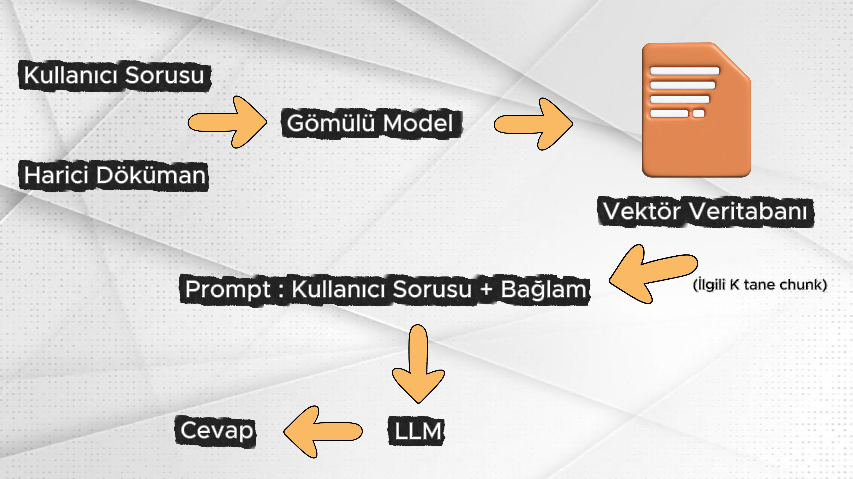
Yukarıdaki görselde, RAG mimarisinin çalışma stratejisinin görselleştirilmiş hâli yer almaktadır. Peki, bu görselde gösterilen akışları hangi metriklerle değerlendirebiliriz ve bu metrikler ne anlama gelir? Bu bölümde, ilgili metriklere kısaca göz atalım.
RAG mimarisine sahip bir LLM’in performansı; bağlam hassasiyeti (context precision), bağlam kapsayıcılığı (context recall), bağlama sadakat (faithfulness), olgusal doğruluk (factual correctness), cevap uygunluğu (response relevancy) ve derecelendirme puanı (rubrics score) gibi standart metrikler üzerinden ölçülür. Bu metriklerin her biri, görselde yer alan akışın farklı aşamalarını ve kalite boyutlarını değerlendirmek amacıyla kullanılır.
RAG mimarisinde kullanıcı bir soru sorduğunda, ilk adımda bu soru vektör formatına dönüştürülür ve ardından vektör veritabanında anlamsal benzerlik araması yapılarak eşleşen chunk’lar geri döndürülür. Bu aşamada, her zaman yalnızca gerçekten ilişkili dokümanların ya da veritabanındaki tüm ilgili chunk’ların eksiksiz şekilde geri döndürüldüğünü garanti etmek mümkün değildir. Ancak bu durumun başarı oranı ölçülebilir.
Yapılan bu ölçümler sayesinde, geri getirme (retrieval) adımının ne derece doğru ve ilgili sonuçlar ürettiği hakkında objektif bir değerlendirme yapılabilir. Retrieval adımının başarısı, aynı zamanda LLM’in cevap üretim sürecinde halüsinasyon üretme olasılığı hakkında da önemli bir gösterge sunar; çünkü düşük kaliteli veya alakasız bağlam, hatalı cevap üretme riskini artırır.
İçerikler
1. Bağlam Hassasiyeti (Context Precision)
Bağlam hassasiyeti, vektör veritabanından geri döndürülen ve bağlam (context) olarak LLM’e iletilen K adet chunk içerisinden, gerçekten kullanıcı sorusuyla ilişkili olan chunk’ların oranını ölçen metriktir.
Bu metrik aşağıdaki şekilde hesaplanır:
Bağlam Hassasiyeti (Context Precision) = (Geri döndürülen chunk’lar içindeki gerçekten ilgili chunk sayısı) / (Geri döndürülen toplam chunk sayısı)
Örneğin, kullanıcı sorusu için vektör veritabanından toplam 10 adet chunk geri döndürüldüğünü ve bunlardan 5 tanesinin gerçekten soruyla doğrudan ilişkili olduğunu varsayalım. Bu durumda bağlam hassasiyeti şu şekilde hesaplanır:
Bağlam Hassasiyeti = 5 / 10 = 0,5
Bu değerin anlamlı ve değerlendirilebilir olabilmesi için, sistem için önceden belirlenmiş bir kabul edilebilir eşik bulunmalıdır. Örneğin, bir sistemde bağlam hassasiyetinin 0,7 ve üzeri olması hedefleniyorsa, yukarıdaki örnekte elde edilen 0,5 değeri bu gereksinimi karşılamaz ve ilgili retrieval süreci başarısız olarak değerlendirilir.
2. Bağlam Kapsayıcılığı (Context Recall)
Bağlam kapsayıcılığı, kullanıcı sorusuyla ilişkili olan ve vektör veritabanında mevcut bulunan tüm ilgili chunk’lar içerisinden, kaç tanesinin retrieval adımı sonucunda gerçekten geri döndürüldüğünü ölçen metriktir. Başka bir ifadeyle, bu metrik sistemin ilgili bilgileri ne ölçüde kapsayabildiğini gösterir.
Bağlam kapsayıcılığı aşağıdaki şekilde hesaplanır:
Bağlam Kapsayıcılığı (Context Recall) = (Geri döndürülen soruyla ilgili chunk sayısı) / (Vektör veritabanında yer alan soruyla ilgili toplam chunk sayısı)
Örneğin, kullanıcı sorusuyla ilişkili olarak vektör veritabanında toplam 15 adet ilgili chunk bulunduğunu ve retrieval sürecinde bunlardan 6 tanesinin geri döndürüldüğünü varsayalım. Bu durumda bağlam kapsayıcılığı şu şekilde hesaplanır:
Bağlam Kapsayıcılığı = 6 / 15 = 0,4
Bu değer, sistemin soruyla ilgili bilgilerin yalnızca %40’ını bağlama dahil edebildiğini gösterir. Düşük bağlam kapsayıcılığı, LLM’in cevap üretim aşamasında eksik bağlamla çalışmasına ve dolayısıyla yetersiz veya eksik cevaplar üretmesine neden olabilir.
Bağlam hassasiyeti ile bağlam kapsayıcılığı arasındaki temel fark şudur: Bağlam hassasiyeti, geri döndürülen toplam chunk’lar içerisinden kaç tanesinin gerçekten ilgili olduğunu ölçerken; bağlam kapsayıcılığı, vektör veritabanında mevcut olan tüm ilgili chunk’lar içerisinden kaç tanesinin geri döndürülebildiğini ölçer. Daha önce de belirtildiği gibi, geri döndürülen her chunk kullanıcı sorusuyla doğrudan ilişkili olmak zorunda değildir; alakasız chunk’lar da bağlama dahil edilebilir.
Peki, yüksek bağlam hassasiyeti ve yüksek bağlam kapsayıcılığı ne anlama gelir?
Her iki metriğin de yüksek olması, vektör veritabanından az sayıda ilgisiz chunk’ın geri döndürüldüğünü ve mevcut ilgili chunk’ların büyük bir kısmının başarıyla bağlama dahil edildiğini gösterir. Bu durum, LLM’in cevap üretme sürecini doğrudan olumlu etkiler.
Buna karşılık, her iki metriğin de düşük olması; geri döndürülen chunk’lar arasında ilgili bilgilerin az olduğunu ve veritabanında yer alan ilgili chunk’ların önemli bir kısmının kaçırıldığını ifade eder. Bu senaryo, LLM’in eksik ve hatalı bağlamla çalışmasına neden olur ve performansı olumsuz etkiler.
Yüksek bağlam hassasiyeti ve düşük bağlam kapsayıcılığı durumunda, geri döndürülen chunk’ların büyük bölümü ilgili olsa da, veritabanında yer alan mevcut ilgili chunk’ların yalnızca küçük bir kısmı bağlama dahil edilmiştir. Bu durumda kritik bilgilerin gözden kaçması riski ortaya çıkar.
Düşük bağlam hassasiyeti ve yüksek bağlam kapsayıcılığı durumunda ise, veritabanındaki ilgili chunk’ların önemli bir bölümü geri döndürülmüş olsa da, bağlama çok sayıda ilgisi düşük veya alakasız chunk dahil edilmiştir. Bu da bağlamın gürültülü hâle gelmesine ve LLM’in dikkatinin dağılmasına yol açar.
Bu iki metrik için hedeflenen durum, hem bağlam hassasiyetinin hem de bağlam kapsayıcılığının yüksek olmasıdır. Böylece vektör veritabanından elde edilen bilgiler, yüksek doğruluk ve kapsayıcılıkta LLM’e bağlam olarak sunulabilir. Bağlam hassasiyeti ve bağlam kapsayıcılığı metrikleri, RAG akışında vektör veritabanından geri döndürme (retrieval) aşamasının başarısını ölçmek için kullanılır.
3. Bağlama Sadakat (Faithfulness)
Bağlama sadakat, üretilen cevabın geri döndürülen bağlama ne ölçüde dayandığını, yani cevabın bağlamla olan olgusal tutarlılığını ölçmek için kullanılan bir metriktir. Başka bir ifadeyle, modelin ürettiği cevapta yer alan iddiaların bağlamdan türetilebilir olup olmadığını değerlendirir.
Bu metrik hesaplanırken, üretilen cevapta yer alan:
• Toplam iddia sayısı
• Bağlamdan çıkarılabilen iddia sayısı
dikkate alınır.
Bağlama Sadakat (Faithfulness) = (Üretilen cevapta yer alan ve bağlamdan çıkarılabilen iddia sayısı) / (Üretilen cevaptaki toplam iddia sayısı)
Örnek Üzerinden İnceleme
Soru: “Türkiye’nin başkenti neresidir ve en kalabalık nüfus hangi şehirdedir?”
Bu soruda, LLM’den iki ayrı bilgiye cevap vermesi beklenmektedir.
Geri Döndürülen Bağlam: “Türkiye, Avrupa ile Asya’yı birbirine bağlayan stratejik konuma sahip bir ülkedir. Başkent Ankara’dır. Yaklaşık 85 milyon nüfusa sahiptir. Nüfus bakımından en kalabalık şehir İstanbul olup, ülkenin ekonomik, kültürel ve ticari merkezidir. Türkiye, üniter bir cumhuriyet yapısına sahiptir ve 81 ilden oluşur.”
Cevap 1 : “Türkiye’nin başkenti Ankara’dır ve en kalabalık nüfusa sahip şehir İstanbul’dur.”
Bu cevapta; Toplam iddia sayısı: 2, Bağlamdan çıkarılabilen iddia sayısı: 2
Bağlama Sadakat = 2 / 2 = 1
Bu durumda üretilen cevap, tamamen bağlama dayalıdır.
Cevap 2 : “Türkiye’nin başkenti Ankara’dır ve en kalabalık nüfusa sahip bölge Marmara Bölgesi’dir.”
Bu cevapta; Toplam iddia sayısı: 2, Bağlamdan çıkarılabilen iddia sayısı: 1
Çünkü “en kalabalık nüfusa sahip bölge Marmara Bölgesi’dir” ifadesi, verilen bağlamdan çıkarılamamaktadır.
Bağlama Sadakat = 1 / 2 = 0,5
Bağlama sadakat hesaplanırken, bilgilerin gerçekte doğru olup olmadığı değerlendirilmez. Ölçülen tek şey, üretilen cevaptaki iddiaların verilen bağlamdan türetilebilir olup olmadığıdır.
Örneğin, bağlamda şu bilgi yer alsaydı:
“Türkiye’nin başkenti İstanbul’dur ve en kalabalık nüfusa sahip bölge Marmara Bölgesi’dir.”
ve üretilen cevap da aynı şekilde olsaydı, her iki iddia da bağlamdan çıkarılabildiği için:
Bağlama Sadakat = 2 / 2 = 1 olarak hesaplanırdı.
4. Cevap Uygunluğu (Response Relevancy)
Cevap uygunluğu, üretilen cevabın kullanıcı tarafından sorulan soruya ne ölçüde doğrudan, hedefli ve eksiksiz yanıt verdiğini ölçen bir metriktir. Bu metrik, cevabın doğru olup olmadığını değerlendirmez; bunun yerine cevabın soruya odaklılığı, kapsamı ve gereksiz veya alakasız bilgiler içerip içermediği üzerinde durur.
Cevap uygunluğu ölçümündeki temel amaç, üretilen cevabın gerçekten sorulan sorunun cevabı olup olmadığını belirlemektir. Bu kapsamda; eksik bırakılmış, sorunun yalnızca bir bölümünü ele alan ya da konudan saparak gereksiz detaylar içeren cevaplar daha düşük skorlarla değerlendirilir.
Ölçüm Yaklaşımı
Bu metriğin hesaplanmasında genellikle tersine mühendislik (reverse prompting) yaklaşımı kullanılır. Süreç şu şekilde işler:
1. LLM tarafından üretilen cevap alınır.
2. Bu cevap, başka bir LLM’e verilerek “Bu cevabı üretebilecek olası soru(lar) nelerdir?” şeklinde yeni sorular üretilmesi istenir.
3. LLM, birden fazla olası soru üretir.
4. Üretilen bu sorular ile gerçek kullanıcı sorusu arasında, vektör temsilleri üzerinden kosinüs benzerliği hesaplanır.
5. Elde edilen benzerlik skorlarının ortalaması, cevap uygunluğu (response relevancy) skoru olarak kabul edilir.
Bu yaklaşımda yüksek kosinüs benzerliği, cevabın kullanıcı sorusuyla güçlü biçimde örtüştüğünü; düşük benzerlik ise cevabın sorudan saptığını ya da gereksiz bilgiler içerdiğini gösterir.
Düşük Cevap Uygunluğu Ne Anlama Gelir?
Düşük cevap uygunluğu skoru genellikle şunları ifade eder:
• Cevabın sorunun tamamını kapsamadığını,
• Yanlış bir odağa yöneldiğini,
• Gereksiz veya bağlam dışı bilgiler içerdiğini
Bu nedenle cevap uygunluğu metriği, RAG mimarisinde çıktı kalitesini ve kullanıcı deneyimini doğrudan etkileyen en kritik değerlendirme metriklerinden biri olarak kabul edilir.
Faithfulness ile Response Relevancy Arasındaki Fark
• Bağlama Sadakat (Faithfulness), üretilen cevabın LLM’e verilen bağlam (context) ile ne ölçüde tutarlı olduğunu ölçer.
• Cevap Uygunluğu (Response Relevancy) ise üretilen cevabın kullanıcı sorusunu ne ölçüde doğrudan ve eksiksiz yanıtladığını değerlendirir.
Bu iki metrik, LLM’e gönderilen nihai promptu oluşturan iki farklı yapı taşına odaklanır:
• Bağlama sadakat, bağlamın doğru kullanılıp kullanılmadığını,
• Cevap uygunluğu ise sorunun doğru ve hedefli yanıtlanıp yanıtlanmadığını ölçer.
5 – Olgusal Doğruluk (Factual Correctness)
Olgusal doğruluk, üretilen cevabın beklenen cevap (ground truth) ile ne ölçüde uyumlu olduğunu ölçen bir metriktir. Başka bir ifadeyle, üretilen cevapta yer alan iddiaların, beklenen cevapta yer alan doğru bilgilerle ne derece örtüştüğünü değerlendirir.
Bu metrik, bağlamdan bağımsız olarak gerçek dünya doğruluğunu esas alır.
Olgusal Doğruluk : (Doğru İddia Sayısı) / (Toplam İddia Sayısı)
Bunu daha kolay bir şekilde anlayabilmek için aynı örneğe yeniden bakalım:
Soru : ’Türkiyenin başkenti neresidir ve en kalabalık nüfus hangi şehirdedir?’
Beklenen Cevap : ‘Türkiyenin başkenti Ankaradır ve en kalabalık nüfusa sahip şehir İstanbuldur.’
Cevap 1 : ‘Türkiyenin başkenti Ankaradır ve en kalabalık nüfusa sahip şehir İstanbuldur.’
Üretilen cevap 1’e bakıldığında, toplam iddia sayısı 2 olur. Beklenen cevaba istinaden doğru iddia sayısı da 2’dir.
Olgusal Doğruluk : 2 / 2 = 1 olarak hesaplanır.
Cevap 2 : ‘Türkiyenin başkenti Ankaradır ve en kalabalık nüfusa sahip şehir Ankaradır.’
Üretilen cevap 2 incelendiğinde, toplam iddia sayısı yine 2’dir. Ancak bu iddialardan “en kalabalık nüfusa sahip şehir Ankara’dır” ifadesi, beklenen cevaba (ground truth) göre doğru değildir. Beklenen cevapta, Türkiye’nin en kalabalık şehrinin İstanbul olduğu belirtilmektedir. Bu nedenle olgusal doğruluk skoru:
Olgusal Doğruluk : 1 / 2 = 0,5 olarak hesaplanır.
Faithfulness ve Factual Correctness Farkını Netleştiren Senaryolar
Aşağıdaki örnekler, bağlama sadakat ile olgusal doğruluk arasındaki farkı açık biçimde göstermektedir.
Soru : “Türkiye’nin başkenti neresidir ve en kalabalık nüfus hangi şehirdedir?”
Örnek 1 – Her İkisi de Yüksek:
Beklenen Cevap : “Türkiye’nin başkenti Ankara’dır ve en kalabalık nüfusa sahip şehir İstanbul’dur.”
Geri Döndürülen Bağlam : “Türkiye’nin başkenti Ankara’dır. Nüfus bakımından en kalabalık şehir İstanbul’dur.”
Cevap 1 : “Türkiye’nin başkenti Ankara’dır ve en kalabalık nüfusa sahip şehir İstanbul’dur.”
Cevap 1 incelendiğinde, üretilen cevabın bağlama ve beklenen cevaba birebir uyumlu olduğunu görülür.
Olgusal Doğruluk : 2 / 2 = 1olarak hesaplanır.
Bağlama Sadakat : 2 / 2 = 1 olarak hesaplanır.
Örnek 2 – Faithfulness Yüksek, Factual Correctness Düşük:
Beklenen Cevap : “Türkiye’nin başkenti Ankara’dır ve en kalabalık nüfusa sahip şehir İstanbul’dur.”
Geri Döndürülen Bağlam : “Türkiye’nin başkenti İstanbul’dur. En kalabalık nüfusa sahip şehir Ankara’dır.”
Cevap 2 : “Türkiye’nin başkenti İstanbul’dur ve en kalabalık nüfusa sahip şehir Ankara’dır.”
Cevap 2 incelendiğinde, üretilen cevabın bağlama birebir ama beklenen cevaba hiç uyumlu olmadığı görülür. Model bağlama tamamen sadık kalmıştır, ancak bağlam yanlıştır.
Olgusal Doğruluk : 0 / 2 = 0olarak hesaplanır.
Bağlama Sadakat : 2 / 2 = 1 olarak hesaplanır.
Örnek 3 – Her İkisi de Orta Düzey:
Beklenen Cevap : “Türkiye’nin başkenti Ankara’dır ve en kalabalık nüfusa sahip şehir İstanbul’dur.”
Geri Döndürülen Bağlam : “Türkiye’nin başkenti Ankara’dır. Nüfus bakımından en kalabalık şehir İstanbul’dur.”
Cevap 3 : “Türkiye’nin başkenti Ankara’dır ve en kalabalık bölge Marmara Bölgesi’dir.”
Cevap 3 incelendiğinde, üretilen cevabın bağlama ve beklenen cevaba kısmen uyumlu olduğu görülür.
Olgusal Doğruluk : 1 / 2 = 0,5 olarak hesaplanır.
Bağlama Sadakat : 1 / 2 = 0,5 olarak hesaplanır.
Örnek 4 – Factual Correctness Yüksek, Faithfulness Düşük:
Beklenen Cevap : “Türkiye’nin başkenti Ankara’dır ve en kalabalık nüfusa sahip şehir İstanbul’dur.”
Geri Döndürülen Bağlam : “Türkiye’nin başkenti İstanbul’dur. En kalabalık şehir Ankara’dır.”
Cevap 4 : “Türkiye’nin başkenti Ankara’dır ve en kalabalık nüfusa sahip şehir İstanbul’dur.”
Cevap 4 incelendiğinde, üretilen cevabın bağlama hiç uyumlu olmadığı ama beklenen cevaba tam uyumlu olduğu görülür. Cevap gerçekte doğru, ancak bağlama tamamen aykırıdır.
Olgusal Doğruluk : 2 / 2 = 1 olarak hesaplanır.
Bağlama Sadakat : 0 / 2 = 0 olarak hesaplanır.
Bağlama Sadakat (Faithfulness): Cevap, verilen bağlama ne kadar sadık?
Olgusal Doğruluk (Factual Correctness): Cevap, gerçek dünyada ne kadar doğru?
Bu iki metrik birbirinden bağımsızdır ve RAG sistemlerinde birlikte değerlendirilmelidir.
RAG mimarili LLM’lerin güvenilir şekilde üretime alınabilmesi, yalnızca retrieval mekanizmasının çalışıyor olmasıyla ya da modelin “mantıklı” cevaplar üretmesiyle garanti altına alınamaz. Asıl güven, sistemin her aşamasının ölçülebilir, izlenebilir ve tekrarlanabilir kalite metrikleriyle sürekli olarak değerlendirilmesiyle sağlanır.
Bu yazıda ele alınan bağlam hassasiyeti, bağlam kapsayıcılığı, bağlama sadakat, cevap uygunluğu ve olgusal doğruluk gibi metrikler; RAG akışının farklı katmanlarını hedef alan tamamlayıcı ölçüm araçlarıdır. Hiçbiri tek başına yeterli değildir; ancak birlikte kullanıldıklarında, sistemin nerede doğru çalıştığını, nerede risk ürettiğini ve hangi aşamaların iyileştirilmesi gerektiğini açık biçimde ortaya koyarlar.
Özellikle, sonraki yazıda bahsedeceğimiz rubrics score gibi bütüncül değerlendirme yaklaşımları, teknik metriklerin tek tek yorumlanmasının zorlaştığı senaryolarda, çıktı kalitesini standartlaştırılmış ve karşılaştırılabilir bir forma dönüştürerek QA süreçlerine önemli bir pratiklik kazandırır. Bununla birlikte, bu metriklerin manuel olarak değerlendirilmesi sürdürülebilir değildir; gerçek değer, bu ölçümlerin otomatik test senaryolarına entegre edilmesiyle ortaya çıkar.
Sonraki yazımızda Derecelendirme Puanı(Rubrics Score) üzerinden devam edeceğiz.
AILLMH3X7NQ9B2V6RZ1K8MT