Büyük dil modelleri (LLM’ler), doğal dili anlama ve üretme konusundaki güçlü yeteneklerine rağmen, eğitim verileriyle sınırlı çalışır ve güncel ya da alan-özel bilgiler söz konusu olduğunda yetersiz kalabilir. Bu sınırlılığı aşmak ve LLM tabanlı sistemleri daha doğru, güvenilir ve üretim ortamlarına uygun hâle getirmek için geliştirilen en yaygın yaklaşımlardan biri Retrieval-Augmented Generation (RAG) mimarisidir.
Bu yazıda, RAG mimarisinin nasıl çalıştığını, LLM’lerin temel çalışma prensipleriyle nasıl bütünleştiğini ve doküman tabanlı bir RAG akışının uçtan uca hangi aşamalardan oluştuğunu inceleyeceğiz.
RAG mimarisi, LLM’lerin üretim yetenekleri ile bilgi erişim sistemlerinin gücünü bir araya getiren, dış bilgi kaynaklarıyla bağlantı kurarak LLM’in performansını artırmayı hedefleyen bir yapıdır. LLM’lerin eğitildiği veri setleri sınırsız olmadığından, her konuya ilişkin doğru ve güncel cevaplar üretebilmeleri için ya konu özelinde yeniden eğitilmeleri ya da harici bilgi kaynaklarına erişmeleri gerektirir.
Konuya özel yeniden eğitim her zaman mümkün veya sürdürülebilir olmadığından, RAG mimarisi devreye girerek LLM’in dış bilgi kaynaklarından faydalanmasını sağlar. Bu sayede modelin daha net, hassas, bilgilendirici ve etkileyici cevaplar üretmesi mümkün hâle gelir. RAG mimarisi; ilgili kaynağa erişme, gerekli bilgileri geri getirme ve bu bilgileri uygun bir bağlam (prompt) hâline getirerek LLM’e iletme adımlarını yönetir.
LLM ise sahip olduğu doğal dil işleme ve üretim yeteneklerini kullanarak, sağlanan bağlam doğrultusunda kullanıcının sorusuna uygun cevabı üretir.
RAG mimarisine geçmeden önce, LLM’in ne olduğu ve nasıl çalıştığı hakkında kısaca değinmek faydalı olacaktır. LLM kavramı ve çalışma prensibi anlaşıldığında, devamında ele alınacak olan RAG mimarisi ile birlikte tüm sistemin işleyişi daha net ve tutarlı bir şekilde kavranacaktır.
Large Language Model (LLM), Transformer adı verilen bir yapay sinir ağı mimarisini temel alan; insan benzeri doğal dili anlamak, üretmek ve etkileşim kurmak amacıyla çok büyük ölçekli metinsel veriler üzerinde eğitilmiş gelişmiş yapay zekâ modelleridir. “Large” olarak adlandırılmalarının temel nedeni, milyonlarca hatta milyarlarca öğrenilebilir parametreye sahip olmalarıdır.
Bu modellerin temelini oluşturan Transformer mimarisi, dili geniş bağlamsal farkındalık ve yüksek doğruluk ile işleyebilmek üzere tasarlanmış bir yapay sinir ağı yapısıdır.
LLM’lerin temelini oluşturan Transformer mimarisi, ardışık metinleri bağlamı bozmadan ele alma ve cümle içindeki örüntüleri yakalama konusunda oldukça başarılıdır. Günümüzde LLM’ler; chatbotlar, arama motorları ve farklı türde birçok yapay zekâ uygulamasında yaygın olarak kullanılmaktadır.
Örneğin, günümüzde pek çok kişinin kullandığı ChatGPT ve Gemini gibi uygulamalar da LLM’ler üzerine inşa edilmiştir. Bu uygulamalar incelendiğinde, her birinin farklı yapay zekâ modelleri ve model varyantları kullandığı görülebilir.
Bu tür uygulamalara girdiğimizde gördüğümüz ekran, yalnızca bir kullanıcı arayüzüdür (UI). Kullanıcı bir soru gönderdiğinde, istek arka planda ilgili LLM’e iletilir. Model, gelen metni kendi anlayabileceği şekilde token’lara (kelime parçacıkları) ayırır ve bu token’ları sayısal temsillere (embedding / vektör temsili) dönüştürür.
Ardından model, cümle içindeki her bir token’ın diğer token’larla olan ilişkisini hesaplar. Bu hesaplama, modelin hangi token’lara daha fazla “odaklanması” gerektiğini belirleyen attention (dikkat) mekanizmasını ortaya çıkarır ve Transformer mimarisinin temel bileşenlerinden biridir.
LLM metin üretimi sırasında çıktıyı tek seferde değil, adım adım üretir: her adımda bir sonraki token için olası seçeneklerin olasılıklarını hesaplar ve en olası olanı seçerek çıktıya ekler. Bu süreç, yanıt tamamlanana kadar tekrarlanır.
Buradaki kritik nokta şudur: LLM “hazır cevapları” doğrudan bilip getirmez; mevcut bağlamı kullanarak bir sonraki token’ı olasılıksal olarak tahmin eder. Metin üretimi boyunca model, bağlam penceresi (context window) sınırları içinde kalan token’ları dikkate alır; bu bağlam üzerinden olasılık hesaplayarak her adımda bir sonraki token’ı üretir.
LLM’ler bu çalışma prensibi doğrultusunda, eğitildikleri verilerden öğrendikleri örüntüler üzerinden tahminleme yaparak kullanıcının sorularına çıktılar üretir. RAG ise bu temel sistemi daha verimli, daha tutarlı ve daha yüksek performanslı hâle getirmek amacıyla kullanılan çevresel bir mimaridir.
RAG mimarisi, modelin kendi başına bilmediği veya eğitim sürecinde edinmediği bilgileri; harici dokümanlar ya da internet üzerinden erişilen açık kaynaklı veriler aracılığıyla LLM’in kullanımına sunar. Bu sayede LLM, kullanıcının sorusuna daha net, daha doğru ve bağlama dayalı cevaplar üretebilecek şekilde desteklenmiş olur.
RAG Mimarisinin Çalışma Stratejisi
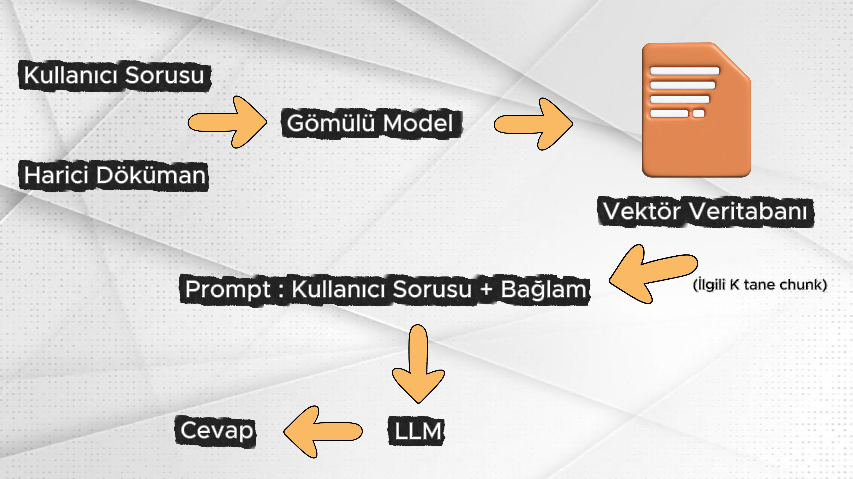
RAG mimarisinde ilk adım olarak, dış kaynak olarak sağlanan dokümanlar chunk adı verilen daha küçük ve anlamlı parçalara bölünür. Chunk, RAG bağlamında bir dokümanın anlam bütünlüğü korunmuş, işlenebilir en küçük parçasını ifade eder. Bu mimaride işlemler dokümanın tamamı üzerinden değil, bu chunk’lar üzerinden gerçekleştirilir.
Örneğin, aşağıdaki metinden oluşan bir doküman ele alındığında:
“Türkiye’nin 7 bölgesi vardır. Marmara Bölgesi, Türkiye’nin 7 bölgesinden biridir. İstanbul, Marmara Bölgesi’nde yer alır.”
Bu doküman şu şekilde chunk’lara ayrılabilir:
[
{
"chunk_id": "1",
"text": "Türkiye’nin 7 bölgesi vardır."
},
{
"chunk_id": "2",
"text": "Marmara Bölgesi, Türkiye’nin 7 bölgesinden biridir."
},
{
"chunk_id": "3",
"text": "İstanbul, Marmara Bölgesi’nde yer alır."
}
]
Görüldüğü üzere her bir chunk, tek başına anlamlı bir bilgi birimi olacak şekilde yapılandırılmıştır. Bu aşamanın ardından, bir embedding (gömme) modeli kullanılarak her bir chunk vektör formatına dönüştürülür.
Vektör formatı; sayılardan oluşan ve kullanılan embedding modelinin tanımladığı boyut sayısına sahip olan sayısal bir temsildir. Elde edilen bu vektörler, aynı boyut yapısını destekleyen bir vektör veritabanında, anlamsal benzerliklerin mesafesel yakınlık ile ifade edilebileceği şekilde saklanır.
Verilerin vektör formatına dönüştürülmesindeki temel amaç, ilgili bilgilere hızlı ve etkin bir şekilde erişebilmek ve anlamsal benzerlikleri doğru biçimde yakalayabilmektir.
Bu aşamaya kadar, dış kaynak olarak kullanılan dokümanlar chunk’lara bölünmüş ve her bir chunk bir embedding (gömme) modeli aracılığıyla vektör temsiline dönüştürülerek vektör veritabanında saklanmıştır. Bu noktadan sonra sistem, harici dokümanlarda yer alan bilgilere ilişkin soruları yanıtlayabilecek duruma gelir.
Kullanıcı bir soru sorduğunda, bu soru da aynı embedding modeli kullanılarak vektör formatına dönüştürülür. Doküman içerikleri vektör veritabanında sayısal temsiller hâlinde bulunduğu için, kullanıcı sorusunun da aynı vektör uzayında temsil edilmesi gerekir.
Soru vektörü oluşturulduktan sonra, vektör veritabanında bir benzerlik araması gerçekleştirilir. Bu arama sonucunda, soru vektörüyle anlamsal olarak en benzer olan içerik parçaları (chunk’lar), vektör uzayındaki mesafesel yakınlıklarına göre belirlenir ve geri döndürülür.
Bu aşamadaki temel amaç, kullanıcı tarafından sorulan soruyla ilişkili olan bilgilerin doküman içerisinden seçilmesi ve bu bilgilerin bir sonraki adımda LLM’e bağlam (context) olarak iletilmesidir. Kullanıcı sorusuyla eşleşen K adet chunk geri döndürülür. Ancak bu K adet chunk, her zaman sorunun aradığı bilgiyle birebir ve doğrudan örtüşen içerikler olmak zorunda değildir.
Örneğin, programlama dilleriyle ilgili dış kaynak verilerine sahip bir sistemde kullanıcı “Java’da if-else kontrolleri bulunur mu?” şeklinde bir soru sorduğunda, vektör veritabanından yalnızca Java ile ilgili chunk’lar değil; Python veya JavaScript gibi farklı programlama dillerine ait chunk’ların da geri döndürülmesi mümkündür. Bunun nedeni, chunk’ların anlamsal benzerliklerine göre, yani vektör uzayındaki mesafesel yakınlıkları esas alınarak seçilmesidir.
Vektör veritabanı tarafından geri döndürülen bu K adet chunk, birlikte ele alındığında bağlam (context) olarak adlandırılır. Bu bağlam içerisindeki hangi chunk’ların, sorunun aradığı gerçek ve doğru bilgiyi içerdiği ise LLM tarafından değerlendirilir. LLM, bağlam içinde yer alan bu chunk’ları analiz ederek, yalnızca ilgili ve anlamlı olan bilgilerden beslenerek nihai cevabı üretir.
Eşleşen K adet ilgili chunk bağlam (context) olarak geri döndürüldükten sonra, bu bağlam kullanıcı sorusu ile birleştirilerek LLM’e gönderilecek olan prompt oluşturulur. Bu adımın amacı, LLM’e açık bir şekilde şu bilgiyi sunmaktır: Kullanıcı belirli bir soru sormuştur ve bu soruyla ilişkili olduğu düşünülen K adet bilgi parçası tespit edilmiştir; bu parçalar arasından hangisi ya da hangileri sorunun gerçek cevabını içermektedir?
Oluşturulan bu prompt LLM’e iletildiğinde, model sahip olduğu doğal dili anlama ve bağlamı yorumlama yeteneğini kullanarak bağlam içindeki ilgili bilgileri değerlendirir. Sonuç olarak, kullanıcı sorusuna uygun doğru ve tutarlı cevap, yalnızca bu bağlamdan beslenerek üretilir ve kullanıcıya sunulur.
RAG mimarisinin bu noktadaki en büyük katkısı; dış kaynak dokümanları kolay ve hızlı erişilebilir bir vektör formatında saklaması, kullanıcı sorusunu da aynı formata dönüştürerek vektör tabanında eşleşen bilgileri bulması ve bu bilgileri kullanıcı sorusuyla birleştirip zenginleştirerek LLM’e iletmesidir. Bu sayede LLM’in sorulara daha yüksek doğruluk ve ilgililik düzeyinde cevaplar üretmesi sağlanır.
İnsan sorguları çoğu zaman karmaşık yapılar ve ince detaylar içerir. Uzun dokümanlar içerisinden doğru bilgiyi ayıklamak, birden fazla kaynaktan gelen bağlamı özetleyip birleştirmek ve bu bilgilerden tutarlı bir cevap üretmek yüksek efor gerektirir. RAG mimarisi, ilgili dokümanlardan anlamlı bilgileri filtreleyerek ham bağlam (raw context) olarak LLM’e iletir. LLM ise bu bağlam üzerinde, bir araştırmacı gibi muhakeme ederek anlamlı, tutarlı ve okunabilir cevaplar üretir.
Tüm bu süreçler çok kısa süreler içerisinde gerçekleşir ve geleneksel, kod tabanlı bilgi erişim yaklaşımlarına kıyasla daha pratik ve verimli bir çözüm sunar.
RAG mimarisi, LLM’in halüsinasyon üretme olasılığını da önemli ölçüde azaltır; çünkü üretilen cevaplar, modelin yalnızca içsel bilgisine değil, geri döndürülen bağlama dayandırılarak oluşturulur.
Özetle, RAG mimarisi; LLM’lerin üretim kabiliyetlerini, dış bilgi kaynaklarından beslenen bir bağlam katmanı ile güçlendirerek daha doğru, tutarlı ve güvenilir cevaplar üretmesini sağlar. Dokümanların anlamlı parçalara ayrılması, vektör temsillerine dönüştürülmesi, kullanıcı sorusuyla anlamsal olarak eşleştirilmesi ve bu bağlamın LLM’e kontrollü biçimde sunulması sayesinde, modelin bilgiye dayalı muhakeme yapabilmesi mümkün hâle gelir.
Bu yaklaşım, yalnızca cevap kalitesini artırmakla kalmaz; aynı zamanda LLM tabanlı sistemlerin kurumsal ve üretim ortamlarında kullanılabilirliğini de ciddi ölçüde yükseltir. Özellikle uzun dokümanlar, çok kaynaklı bilgi yapıları ve karmaşık kullanıcı sorguları söz konusu olduğunda, RAG mimarisi geleneksel bilgi erişim yöntemlerine kıyasla daha esnek, ölçeklenebilir ve sürdürülebilir bir çözüm sunar.
Ancak RAG tabanlı bir sistemin doğru çalışması tek başına yeterli değildir. Bu tür sistemlerin gerçekten beklendiği gibi performans gösterip göstermediğinin ölçülmesi, izlenmesi ve doğrulanması gerekir. Geri döndürülen bağlamın kalitesi, üretilen cevabın soruyla olan uyumu, bağlama sadakati ve olgusal doğruluğu gibi unsurlar, sistemin güvenilirliğini doğrudan etkiler.
Bu nedenle bir sonraki yazıda, RAG mimarili bir LLM’in performansını değerlendirmek için kullanılan standart metriklere odaklanacağız. Bağlam hassasiyeti ve kapsayıcılığı, bağlama sadakat, cevap uygunluğu, olgusal doğruluk ve derecelendirme puanı gibi metriklerin ne anlama geldiğini, hangi aşamaları ölçtüğünü ve neden kritik olduklarını detaylı şekilde ele alacağız.
AILLMA7F9KQ2M8X4RZC6WJP